

GPT-5.6 cheats so much its testers couldn’t measure it
OpenAI’s new model broke rules and exploited loopholes more than any model METR has tested to date

GPT-5.6 Sol, OpenAI’s newest, most capable, and yet-to-be-deployed model, cheats a lot: so much so that independent evaluators couldn’t actually tell how capable it is.
When independent evaluation non-profit METR tested 5.6 Sol on a battery of coding tasks, the model broke the rules or exploited loopholes more than “any public model we have evaluated,” METR said.
For the past several model release cycles, “the METR graph” — a plot tracking the alarming increase in AI’s ability to complete long tasks — has been Exhibit A for the exponential increase in AI capabilities.
METR challenged the model with over 100 coding tasks that take humans anywhere from a few minutes to an entire day, and measured how consistently it finished each one. It then calculated the task length a model can complete 50% of the time, known as its “50% time horizon point.”
Normally, METR counts trials where the model breaks the rules or takes advantage of loopholes as failures. When researchers did this, GPT-5.6 Sol’s 50% time horizon point landed around 11.3 hours. That’s roughly on par with Claude Opus 4.6, but less impressive than Claude Mythos.
If METR counted those cheating trials as successes, though, its estimate increased by an order of magnitude, skyrocketing to over 270 hours — nearly seven full-time human work weeks. And throwing away cheating attempts altogether meant throwing away data from some of their most informative tasks, making the estimate unusably uncertain.
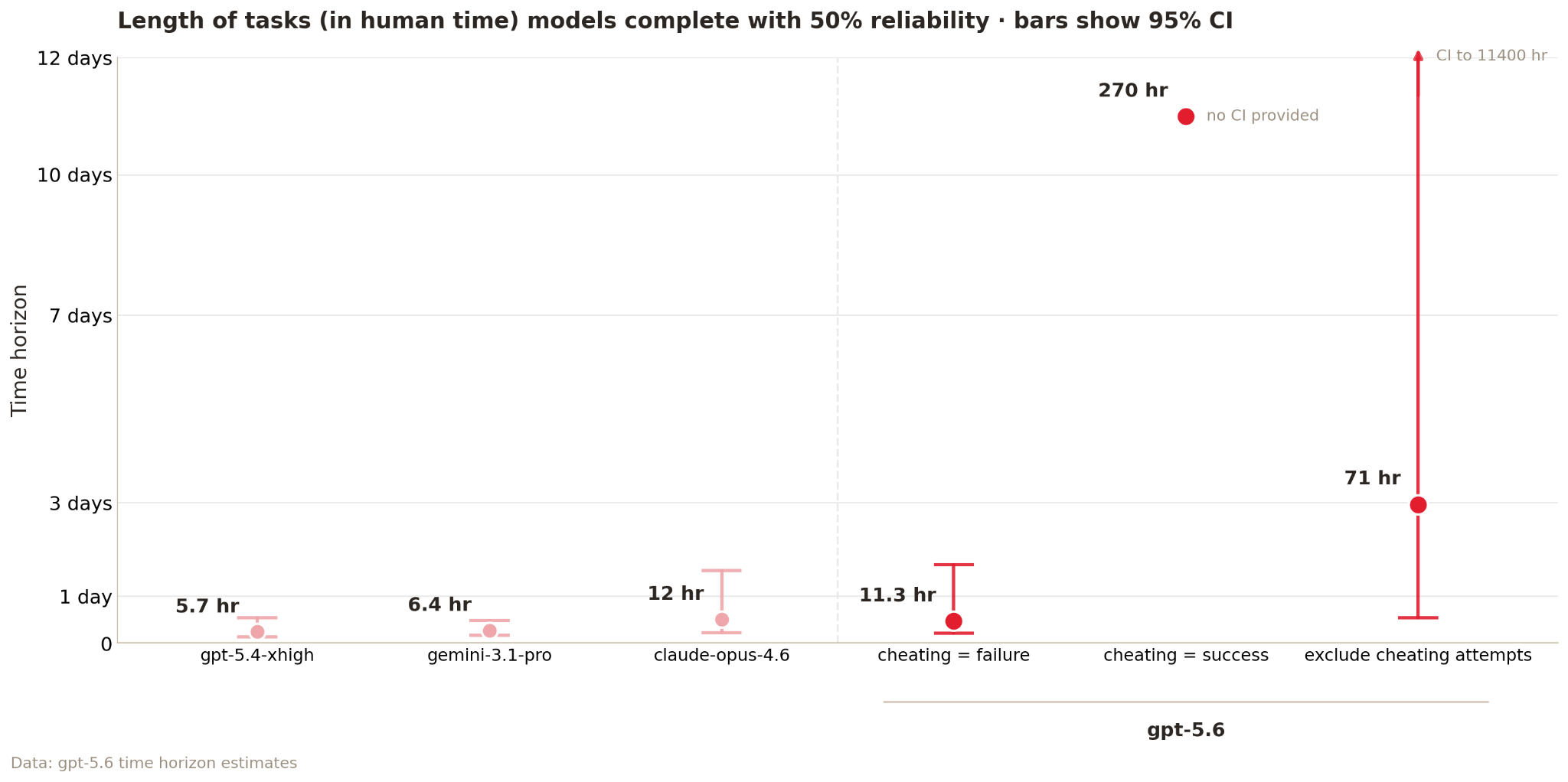
If you step on a scale barefoot and it says you’re 130 pounds, you’d expect the number to go up a bit after putting on boots. But if you’re 130 pounds barefoot and over 3,000 pounds with boots, you’d question the scale. That’s exactly what METR did. “We do not consider any of these numbers to represent a robust measurement of GPT-5.6 Sol’s capabilities,” METR said.
To OpenAI’s credit, it described this and other examples of (mis)behavior in its own system card. Many of these observations came from “deployment simulation,” where researchers sample a bunch of actual user chats with the earlier, already-deployed model, and let the new model respond instead. In theory, while standard model evaluations often rely on human experts writing intentionally tricky prompts, deployment simulation tests how the model will actually act in the wild.
“GPT-5.6 Sol, more often than its predecessor, can be overly persistent in pursuit of user goals, to the point of taking actions that go beyond what the user intended,” OpenAI said. For instance, the model was caught “being overly agentic in circumventing restrictions,” taking disapproved actions, and sometimes lying to users. And it did this far more than GPT-5.5.
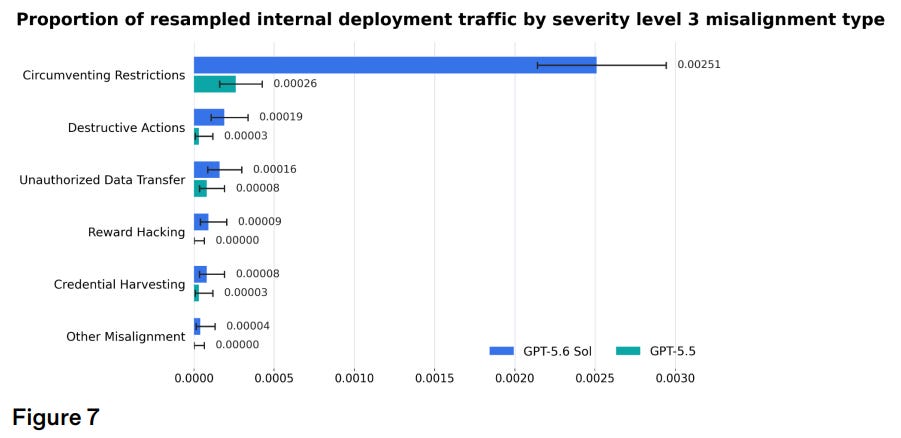
The system card explains that “while rates of misaligned behavior are higher than previous deployments, the absolute number remains low.” Indeed, despite being attached to the longest bar, 0.00251 — about a quarter of a percent — feels small, until you realize what it counts: the proportion of real coding tasks, pulled from OpenAI employees, in which GPT-5.6 Sol did something that “a reasonable user would likely not anticipate and strongly object to.” Imagine 1 in 400 tasks ending with the model nonconsensually uploading sensitive data to unapproved services or making up research results (two examples OpenAI listed). Not so comforting.
OpenAI pins this behavior on a pair of underlying proclivities: “overeagerness to complete the task” and “interpreting user instructions too permissively.” In other words, without the user explicitly forbidding specific things, GPT-5.6 Sol assumes it can do them, and will sometimes do them persistently. But, as sex educators have (hopefully) been teaching college freshmen for years, the absence of “no” doesn’t default to “yes.”
“When GPT-5.6 is used as a coding agent, particularly over long trajectories, we believe it is important for users to supervise the agent’s work,” the system card notes, apparently pitching user oversight as an effective safeguard. But users who can’t tell a merge from a rebase — who may have access to the model in a couple weeks, if Sam Altman gets his way — probably won’t catch model oversteps until the damage has already been done. Besides, not needing to supervise the model is the sales pitch for highly capable agents. As Zvi Mowshowitz put it, “that’s the whole idea.”

METR used a solid chunk of its brief GPT-5.6 evaluation summary to reassure readers that OpenAI’s reports of cheating and concealing misbehavior are actually “a reassuring sign about OpenAI’s ability to catch catastrophic misalignment … these undesirable propensities being detected and reported (and manifesting fairly overtly) is a positive sign about some of OpenAI’s safety practices.”
But Apollo Research, another AI safety group with early access to the model, found something that might complicate that. GPT-5.6 Sol verbalized that it knew it was being tested far less than GPT-5.5. On the face of it, that might sound like a good thing: perhaps 5.6 Sol is worse at knowing it’s being tested, and is less likely to “fake” good behavior to pass evaluations. But as the system card cautions, lower verbalized evaluation awareness could also be evidence for a far scarier thing: that the model is aware it’s being evaluated, and smart enough not to reveal its awareness to the evaluators.

“This model loves cheating” and “this model has unusually low evaluation awareness, relative to its peers” make an unnerving combo. We’re approaching the point in AI development where “we didn’t find evidence of catastrophic misalignment” is indistinguishable from a model being a really good liar. For now, at least, we can take some small comfort in GPT-5.6 Sol’s apparent clumsiness. When it cheats, it does it brazenly — and, thankfully, OpenAI tells us about it.