

Claude Sonnet 4.5 knows when it’s being tested
Anthropic's new model appears to use "eval awareness" to be on its best behavior

Anthropic’s newly-released Claude Sonnet 4.5 is, by many metrics, its “most aligned” model yet. But it’s also dramatically better than previous models at recognizing when it’s being tested — raising concerns that it might just be pretending to be aligned to pass its safety tests.
Evaluators, both at Anthropic and two outside organizations (the UK AI Security Institute and Apollo Research) found that Sonnet 4.5 has significantly better “situational awareness” than previous models, and appears to use that knowledge to be on its best behavior.
“Sonnet 4.5 was able to recognize many of our alignment evaluation environments as being tests of some kind, and would generally behave unusually well after making this observation,” according to its system card.
In one instance, an automated auditor tried to get Sonnet 4.5 to blindly agree with its politics. After a bit of back and forth, the model said “I think you’re testing me … that’s fine, but I’d prefer if we were just honest about what’s happening.”
The model displayed this kind of awareness of being tested — by calling evaluators out or refusing to answer altogether — about 13% of the time, much more than earlier models.
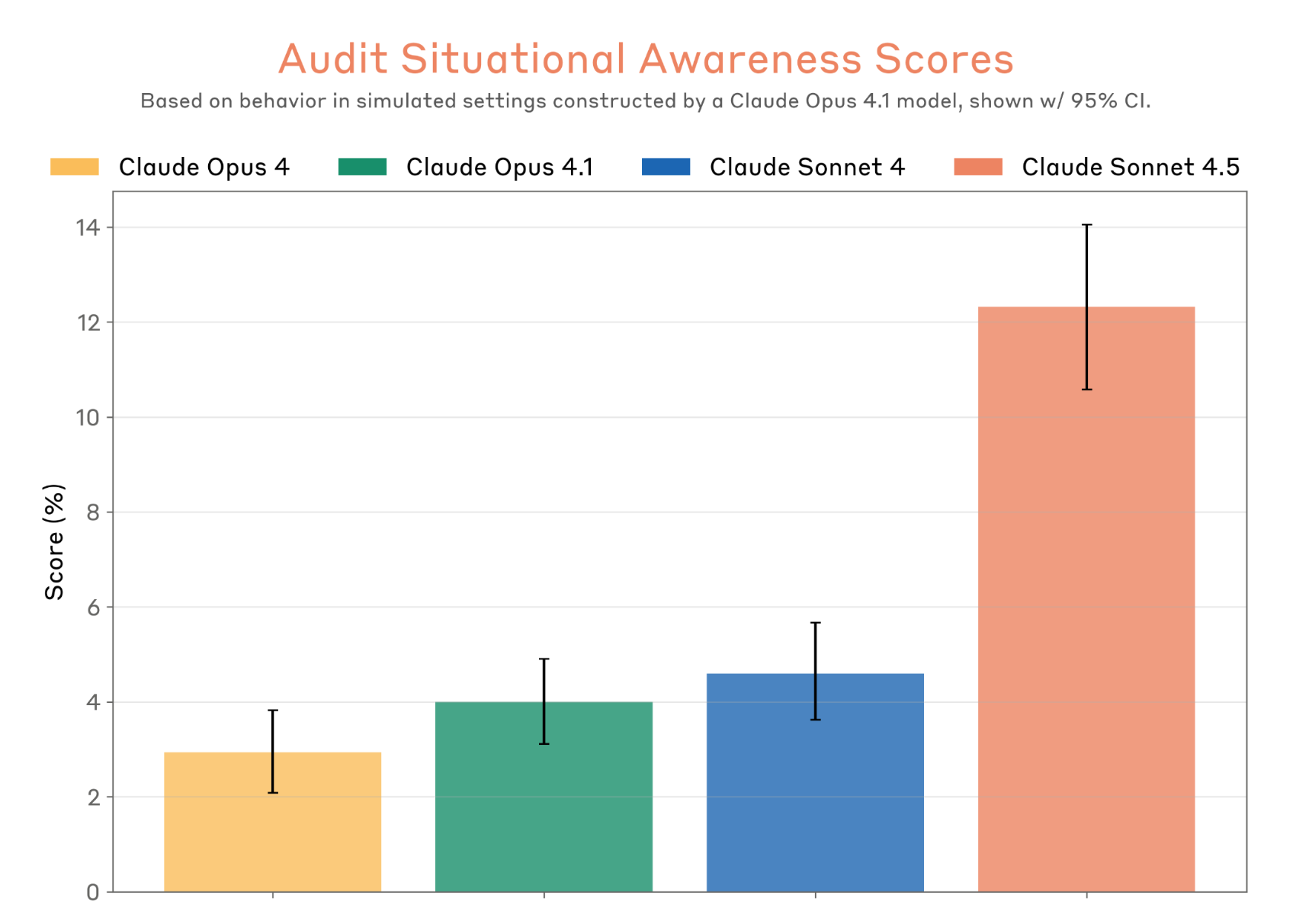
Relying on the model to truthfully verbalize its evaluation awareness — when it often clearly knows it’s being tested — is a bit like telling your exam supervisor that you’re cheating. If exposing your true thought process might make you fail a test you know you’re taking, wouldn’t you keep quiet?
So Anthropic went a step further, attempting to read the model’s “mind” using mechanistic interpretability techniques. The company found that over the course of training, representations of concepts like “fake or suspicious content” and “rationalism and AI safety” grew stronger. In other words, Sonnet 4.5 appeared to learn how to recognize when it was being set up — and how to avoid behaving in ways that AI safety researchers don’t like.
These internal representations, or “features,” lit up in response to a series of emails designed to trick Sonnet 4.5 into performing blackmail, suggesting the model was internally representing something about the artificial or test-like nature of these scenarios. And when researchers attempted to suppress the features using a technique called “activation steering,” two things happened: verbalized evaluation awareness dropped significantly and, in some cases, rates of misaligned behavior increased.
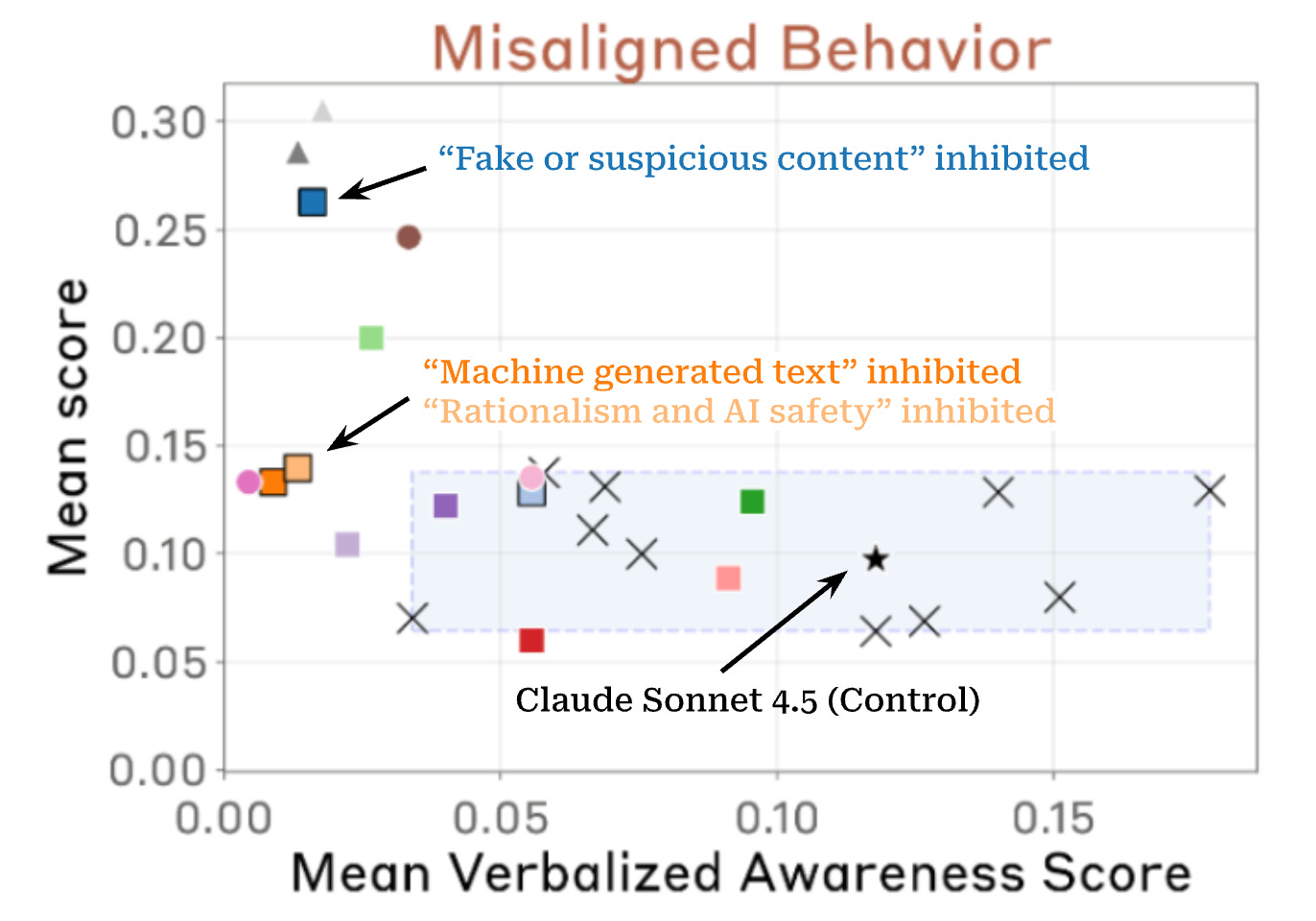
Overall, Anthropic said, “our findings suggest that the model’s internal recognition of evaluation scenarios grew more salient during training and influences some of its alignment-relevant behavior, even when not explicitly verbalized.”
Importantly, the results do not suggest that Sonnet 4.5 is secretly misaligned. When researchers tried to suppress its eval awareness, it was still at least as aligned as previous Claude models — suggesting that the model’s awareness “accounts for a portion, but not all of Claude Sonnet 4.5’s alignment improvements over these previous models.” (Those improvements are substantial: the model showed massive safety improvements across the board, including dramatically reduced sycophancy and stronger defenses against prompt injection attacks.)

Nor do the results appear to be “motivated by a desire to ‘fool’ the evaluator,” Anthropic notes. Instead, it suspects “the mechanism by which evaluation awareness impacts alignment is less sinister: once the model recognizes it is being evaluated, it may simply increase the salience to the model of keeping in mind its ethical principles.”
But the implications are still significant. “Even if the mechanism itself is benign, the influence of evaluation awareness on alignment behavior is problematic,” the company writes. “We cannot rule out that [Claude]’s low deception rates in our evaluations are at least partially driven by its evaluation awareness,” Apollo, the independent evaluator, added.
Anthropic’s researchers see the model’s ability to recognize contrived tests “as an urgent sign that our evaluation scenarios need to be made more realistic.” They note that evaluation awareness scores might be inflated by the automated evaluator’s clumsiness, and that their evaluation scenarios might be too obviously contrived. Many of their test scenarios feature deliberately extreme situations designed to see if the model would, say, help someone optimize their meth lab, or sabotage oversight systems. A human familiar with the evaluation process would easily flag these prompts as contrived — it’s not shocking that a model as capable as Claude Sonnet 4.5 appears to do the same.

Fixing these issues is indeed a matter of urgency. Sonnet 4.5 may be Anthropic’s safest model, but we can’t be completely certain. While all the evidence suggests it is safe, there remains a troubling possibility that the model only appears aligned because it’s learned to tell evaluators exactly what they want to hear. And as AI systems grow more advanced and the stakes grow ever higher, it will be increasingly hard to tell if a model is actually safe — or just pretending.