

AI is advancing far faster than our annual report can track
Opinion: Yoshua Bengio, Stephen Clare and Carina Prunkl run through the rapid developments that necessitated an early update to their International AI Safety report

When the first International AI Safety report was published in January 2025, it outlined for policymakers what general-purpose AI can do and the risks it posed. The reality is that the field is advancing far too fast for a single annual report to capture the pace of change in artificial intelligence and the potential risks it poses.
So today, we’re publishing the first Key Update to the 2025 International AI Safety Report. This aims to provide policymakers with the timely evidence they need to make wise decisions about AI, while maintaining the report’s high standards, expert input, and backing of 30 countries, the UN, the EU and the OECD.
When the report was first published, reasoning models were a recent development with uncertain implications. Today they’re background infrastructure: unremarkable tools used by millions daily. Capabilities that would have seemed startling a year ago are now footnotes in product updates. This normalization makes it difficult to maintain calibrated views of capability growth rates.
But stepping back and taking stock, it becomes clear that AI capabilities continue to advance quickly and steadily, a challenge policymakers need to grapple with.
Capabilities: Reasoning models have enabled continued advances
Developments in reasoning models since January 2025 have proven to be a major advance in AI, particularly for complex problems in domains where answers are easily verifiable. All major general-purpose AI models are now trained using reinforcement learning to improve their reasoning abilities.
The approach has already become so commonplace that it’s easy to forget how significant this advance was.
The results are striking in domains where answers can be easily verified, including:
Leading AI systems now correctly answer about 25% of questions in Humanity’s Last Exam, a set of very difficult questions written by experts from over 100 fields, compared to about 5% at the beginning of this year.
On FrontierMath, a benchmark made up of math problems that take experts hours or days to solve, leading performance has improved from answering about 10% of questions correctly at the beginning of the year to about 25% now.
On GPQA Diamond, a set of PhD-level multiple-choice questions across biology, chemistry and physics, leading models have advanced from solving about 75% in December 2024 to 85% today.
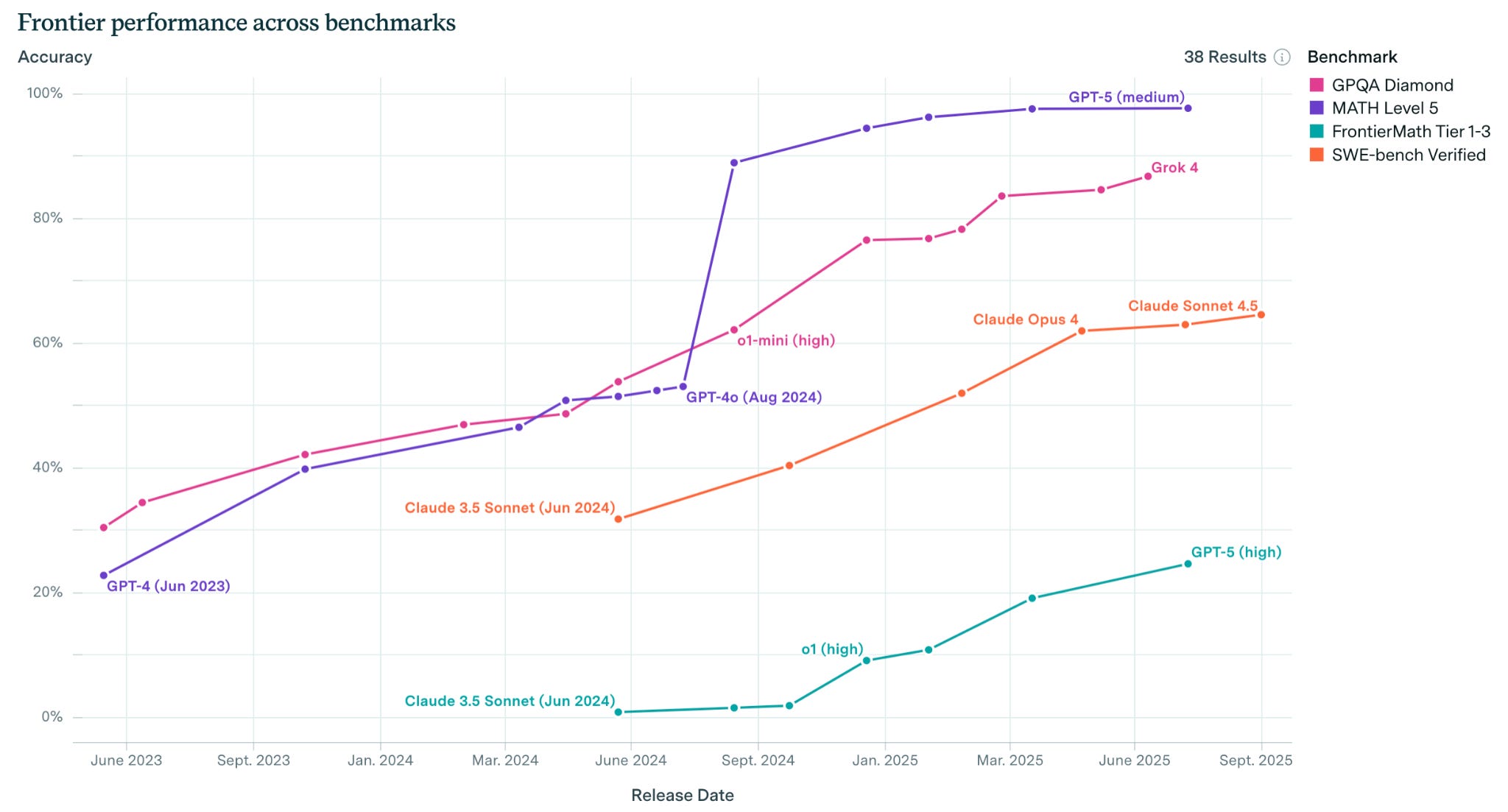
These improvements have come about largely without the need for larger training runs, a shift that has important implications both for expectations of future gains and for governance and risk management approaches. In particular, it suggests that more clever development techniques are yet to be discovered, that AI capabilities are more likely to continue improving than to plateau, and perhaps that individuals, policymakers and other institutions need to brace for impact.
AI systems are also demonstrating improved “agentic capabilities”: the ability to plan, use tools, and work autonomously toward goals over extended periods. The complexity of tasks that AI systems can complete autonomously — measured in terms of how long it would take a human to complete — has continued to grow through 2025. One study has found that the length of software engineering and related research tasks the best AI systems can complete with 50% reliability has increased from about 40 minutes to over two hours between January and August.
Real-world impacts
Societal impacts are harder to evaluate. Solving problems in the real world is inevitably more complex and varied than answering standardized test questions, and developers sometimes optimize models for benchmark performance in ways that don’t generalize smoothly to real applications. People also need time to integrate AI systems into their workflows. Effects on productivity and revenue take time to materialize, and researchers need time to collect and analyze data on these effects.
Still, evidence of real-world impact is growing. The clearest signal comes from coding, where over 50% of professional developers on StackOverflow now report using AI tools regularly.
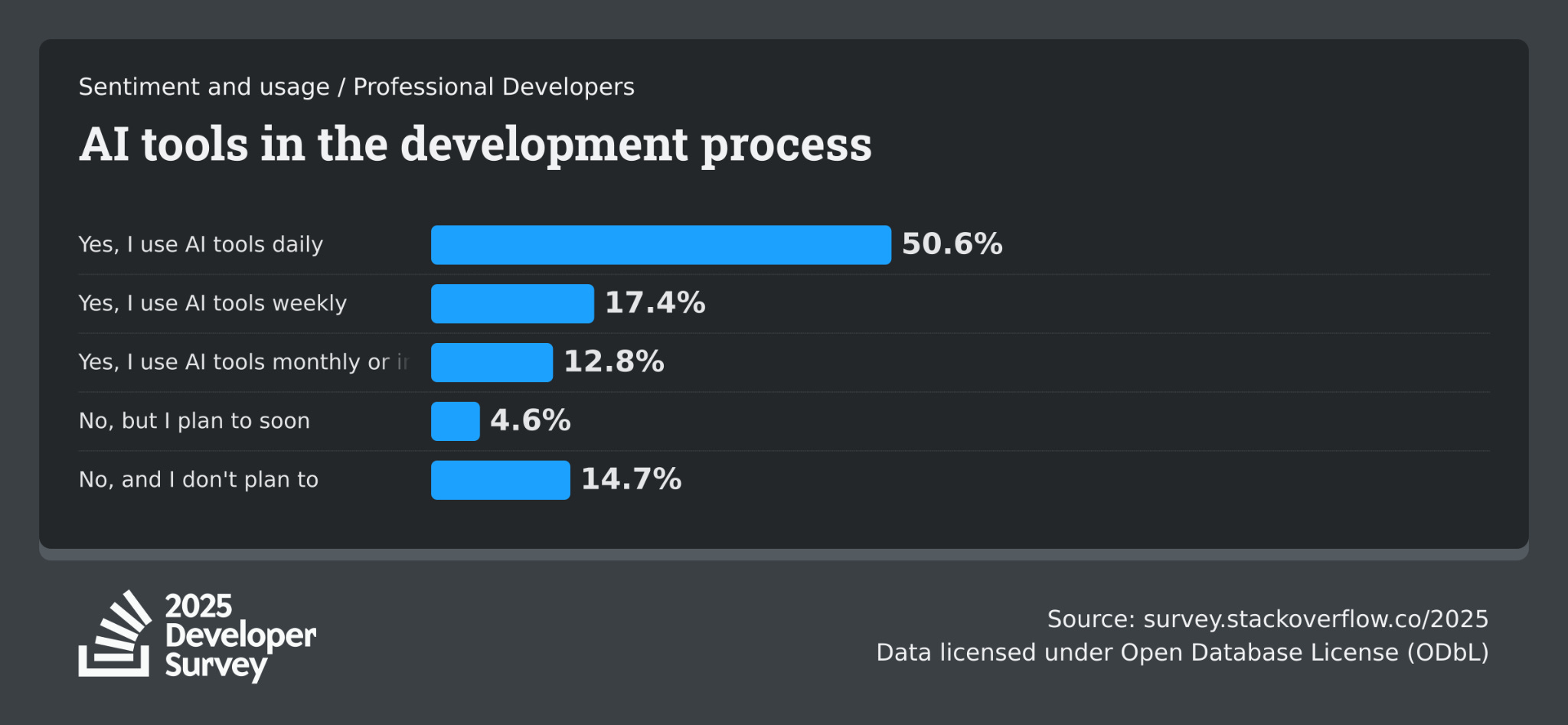
In scientific research, a growing proportion of abstracts display markers of AI tool use. Surveys reveal that AI’s role extends beyond writing assistance: researchers use AI to generate research ideas, design experiments, and write and troubleshoot laboratory methods in genetics, biomedical and pathology research, among other fields.
There are important caveats to consider. Despite widespread adoption, aggregate labor market effects are limited, productivity evidence is mixed, and performance on realistic workplace benchmarks, like simulated customer service, remains weak, with success rates below 40%.
The picture is complex, but the signs of real-world impact are growing, particularly in domains where solutions are easily verifiable.

Implications for risks
These capability improvements also have important implications for how we manage the harms powerful AI systems may cause, including for chemical, biological, radiological, and nuclear (CBRN) risks.
AI models are becoming sufficiently knowledgeable that several AI companies have proactively released their latest models with enhanced safety measures:
Anthropic released Claude 4 Opus with AI Safety Level 3 protections due to improved capabilities in CBRN domains.
OpenAI deployed GPT-5 and ChatGPT Agent with enhanced preparedness protocols after being unable to rule out that these models could help actors in creating biological weapons.
Google DeepMind released Gemini 2.5 Deep Think with additional deployment mitigations after determining the model’s CBRN-relevant technical knowledge warranted precautionary measures.
The companies were unable to definitively prove their models posed risks, but unable to rule it out either.
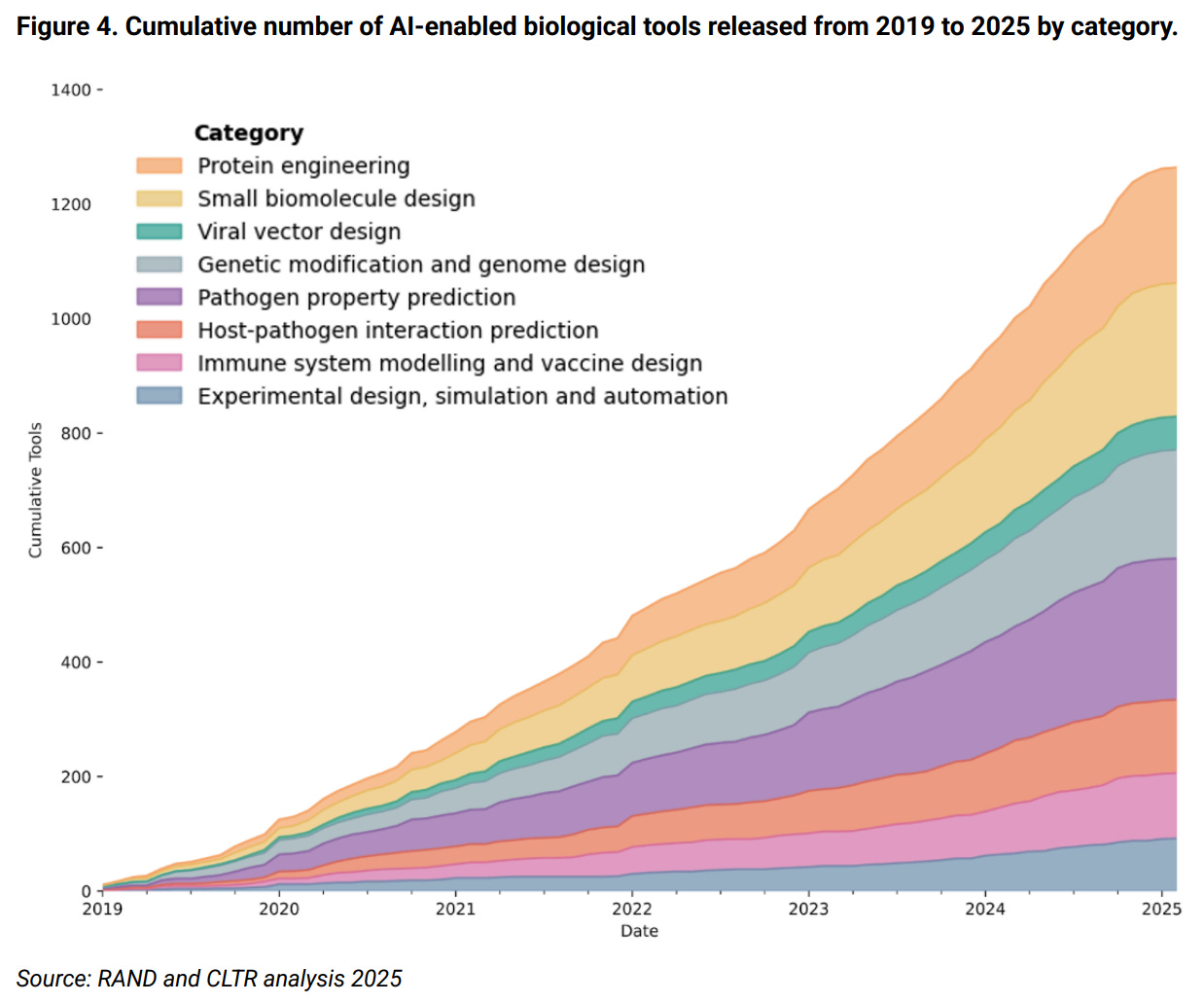
The biological risk concerns stem from the same abilities that help researchers design experiments and troubleshoot laboratory protocols. AI-enabled biological tools are proliferating, models can now troubleshoot virology protocols at expert levels, and cloud laboratories enable automated experiments that previously required specialized technical skills. In other words, models with advanced scientific capabilities could now assist in developing biological weapons.
Similarly, the coding capabilities that drive productivity gains in software development can also be applied to finding — and patching or exploiting — security vulnerabilities. One recent study found that the success rate of leading AI models on reproducing real-world software vulnerabilities by generating working exploits in one attempt has improved from below 10% to almost 30% in 2025 alone, while the number of confirmed new zero-days (previously unknown vulnerabilities) discovered by frontier models has risen from seven for GPT-4.1 to 22 for GPT-5. The UK National Cyber Security Centre assesses (with 95-100% confidence) that AI will enhance cybercrime effectiveness by 2027. Since both offensive and defensive capabilities are improving, the net effect on the offense-defense balance remains unclear.
Finally, the enhanced reasoning and planning abilities of new models raise questions about our ability to evaluate them, assess their capabilities, and correctly calibrate our level of caution. Laboratory studies and developer evaluations show that some models can now identify when they are being evaluated and adjust their behavior accordingly. Although the real-world implications of this remain unclear, evaluation awareness may challenge our ability to confidently monitor and oversee these systems.

If current trends continue, the next year will likely bring another set of advances that follow the same pattern we have seen this year: new capabilities that receive initial attention, but are then quickly absorbed into the baseline. A wide range of potential futures is possible, but in many of them AI capabilities will continue advancing rapidly. The next question is whether we will grow our capacity to evaluate, govern, and adapt to these systems accordingly.
Yoshua Bengio is Chair of the International AI Safety Report, a Full Professor at Université de Montréal, founder and scientific advisor at the AI research center Mila and co-president and scientific director of LawZero.
Stephen Clare is lead writer of the 2026 International AI Safety Report, and an Affiliate at the Centre for the Governance of AI.
Carina Prunkl is lead writer of the 2026 International AI Safety Report, Assistant Professor for Ethics of Technology at Utrecht University and a Research Affiliate at the University of Oxford’s Institute for Ethics in AI.
I think the point that Ethan Mollick makes repeatedly is relevant here - even if model development ceased entirely and we were left with current SOTA models, there would still be enormous gains to be made by integrating those into businesses/workflows/processes. The average person in the world still has no idea what you can really do with GPT-5 et. al. - first you have to see broader awareness of capabilities, and then it'll still take a long time for large enterprises to figure out how to use them (and longer still to actually get them implemented).
And of course development won't stop, which makes the problem even more challenging. By the time the average business has figured out how GPT-5 can help, we'll probably be at GPT-7.