

AI models are getting really good at things you do at work
A new OpenAI benchmark tests AI models on things people actually do in their jobs — and finds that Claude is about as good as a human for government work

Everyone’s been asking when AI will take our jobs, but almost nobody has systematically measured whether models actually can.
OpenAI’s new GDPval benchmark, introduced last Thursday, is the first serious attempt to test whether AI can do the work that keeps the economy running — not just coding, but writing legal briefs, putting together slide decks, and making sales forecasts.
Expert human graders blindly compared outputs from models and humans, and rated one as “better,” “as good as,” or “worse than” the other.
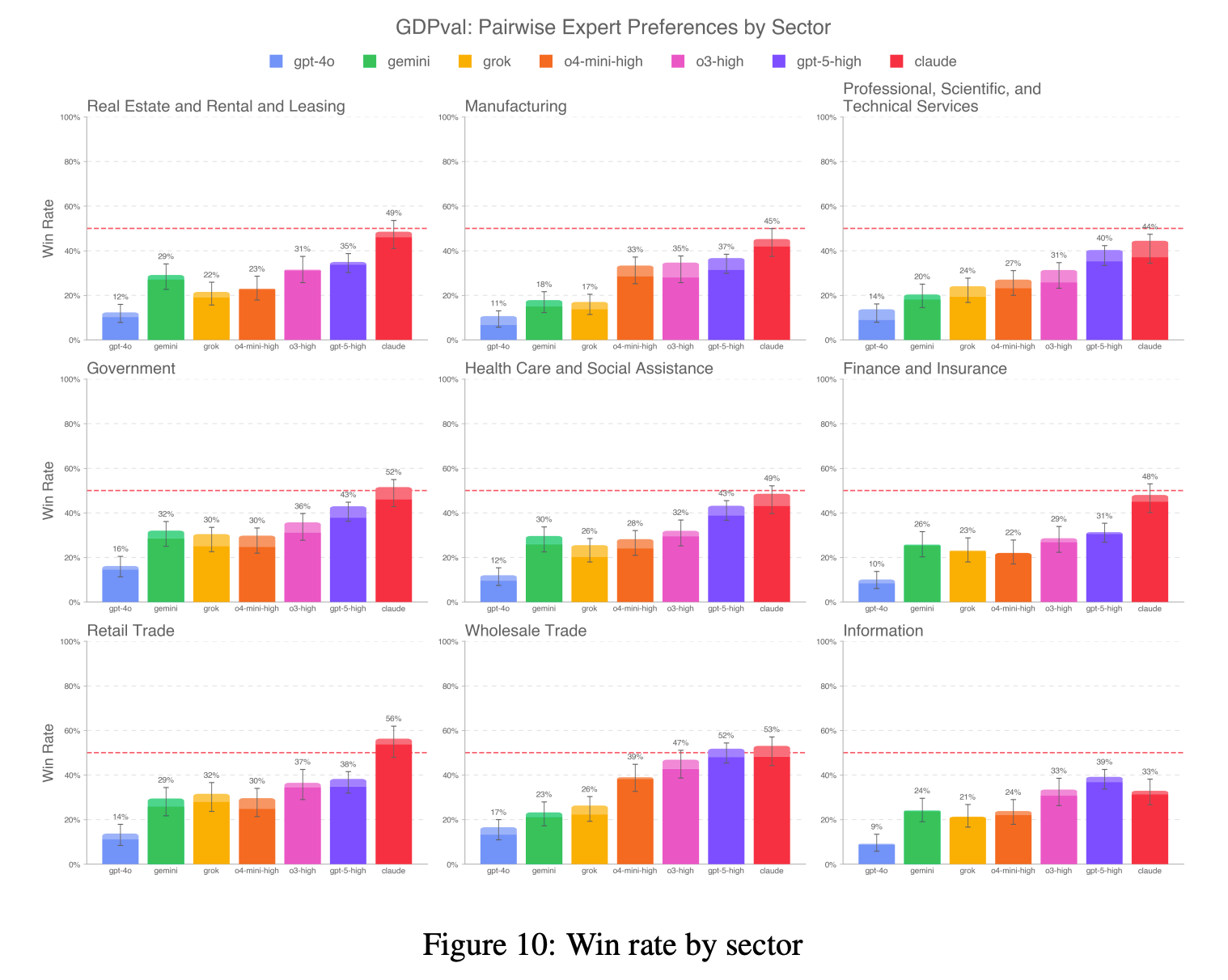
Claude Opus 4.1 came very close to matching human performance across nearly all job sectors, performing particularly well on tasks from the retail, wholesale and government sectors.
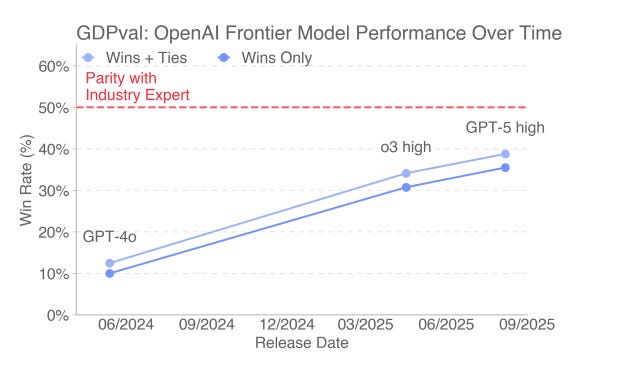
The pace of progress is also notable. OpenAI models’ win rate climbed from roughly 10% to 35% over the last year.
Broken down by profession, the results show a clear pattern: AI is already capable of handling discrete, well-defined projects where all the necessary context fits in a text prompt. Tasks accounting for much of the work of government grants management specialists, software developers, and editors — carried out on computers and with clear outputs — are matched or outpaced by Claude, according to the study.
The new study is notable for its rigorous methodology — a stark contrast with older benchmarks. Until very recently, the most popular benchmarks for evaluating LLMs — like MMLU (Massive Multitask Language Understanding), a test for undergrad-level knowledge — involved throwing the model exam-style questions via text. When MMLU was introduced in 2020, it stumped most existing models with multiple-choice math questions. But by this time last year, models like Claude 3.5 Sonnet and GPT-4o were already close to acing several traditional benchmarks, including MMLU.
Newer evaluations such as SWE-Bench, MLE-Bench, and Paper-Bench raise the ceiling on performance by challenging models with harder engineering and scientific reasoning tasks, but they only capture a tiny slice of work people actually do for a living.
To try to fix that, OpenAI worked with industry experts — professionals with at least four years of experience in their field, and an average of 14 years — to design tasks that real people might have to do at work, such as using reference files to create social media posts, spreadsheets, and slide decks.
GDPval includes tasks from 44 occupations across nine different economic sectors, testing LLM capabilities in everything from real estate to reporting. While this is still far from representative of the entire American workforce, it does span a wide range of “predominantly digital” jobs. (If you can do at least 60% of your work tasks on a laptop, there’s a solid chance you’ll find your career in GDPval’s task list.)

One task, for instance, has the model be a “police department firearms training coordinator assigned to develop a formal report for the Chief of Police regarding the procurement of new duty rifles for departmental issuance.”

While no models tested outperformed humans at every job task, both GPT-5 (with reasoning effort set to “high”) and Claude Opus 4.1 were usually judged to be better than humans at software development — perhaps unsurprisingly, given AI developers’ focus on automating their own jobs.

LLMs did not match humans at all types of knowledge work, though. Models seemed to succeed at one-shot tasks where all the context — a brief, a dataset, a clear set of requirements and formatting guidelines — is laid out in front of them. They appeared to do less well in many occupations that require slowly building connections over time, reading between the lines to understand what a client actually wants, or making judgment calls based on more than data.
GDPval helps to ground conversations about job loss in actual model performance, rather than fear and wild speculation. It also shows that “Will AI take our jobs?” isn’t a yes or no question.
Of course, the benchmark is far from perfect. Recruiting and paying a bunch of experts to design tasks, grade results, and draft scoring rubrics is prohibitively expensive for anyone without OpenAI-sized piles of cash. With this in mind, researchers trained an automated grader, which they’ve made openly available alongside a “gold” subset of 220 tasks. However, the paper emphasizes that they “do not consider it a full substitute for industry expert graders.”
These real-world tasks also run up against a classic science dilemma: experiments can be highly controlled, or they can reflect the real world, but they can rarely do both.
Each individual expert helped to design tasks that reflected their understanding of “representative” tasks for their profession, but coming up with a collection of tasks to best represent one’s job is quite hard. One recreation worker — a camp director, for example — might think that “managing activities and equipment rentals” captures most of their experience, while someone who works at a city community center might spend much more time scheduling facility usage and doing administrative paperwork.
On the other side of the evaluation, judging whether one work output is “worse” or “better” than another is inherently subjective. While evaluators made rubrics to explain their scoring criteria, it’s possible that different graders might not weigh factors like factual accuracy, aesthetics and usability equally.
These self-contained projects also can’t capture the things that happen between “tasks” at work: showing up to meetings, gossiping about industry news over lunch or building trust with clients over time, for example.
In a blog post accompanying the paper, OpenAI stuck to its recent messaging that AI won’t replace jobs (despite what Sam Altman has previously said): “Most jobs are more than just a collection of tasks that can be written down. GDPval highlights where AI can handle routine tasks so people can spend more time on the creative, judgment-heavy parts of work.”
That framing sounds optimistic — enticing, even! — until you consider how workplaces and careers actually function.
Handling routine tasks is how new employees learn the ropes. Junior lawyers don’t start arguing before the Supreme Court — they spend years drafting memos. Young scientists do their labs’ dirty work to develop an intuition for how experiments succeed or fail in practice. If models can handle most of the “collection of tasks that can be written down,” many companies will stop hiring people to do them. The bottom rungs of the corporate ladder disappear, and the path to expertise vanishes with them. And if AI capabilities keep advancing, even those “creative, judgment-heavy” parts of work may not stay protected for long.
If that does happen, GDPval may end up providing an early warning signal, helping us move beyond speculation to real measurement. The implications are unsettling, but at least now we’re working with evidence instead of panic. That’s progress, even if it doesn’t feel like it.