

Where have the really big AI models gone?
Why the race to scale up pretraining isn’t over

For most of the past half-decade, AI progress has been powered by ever greater amounts of computing power. Each major model has been trained on orders of magnitude more data than its predecessor, with gains so consistent they became known as scaling laws.
That was until last fall, when headlines touted that scaling was dead. Companies were reportedly no longer seeing sufficient returns to continue their headlong dash to scale pretraining compute.
The release of GPT-4.5 in February, widely seen as disappointing, seemed to support these claims and reinforce growing skepticism about scaling within AI companies. Josh You, data analyst at research organisation Epoch AI, says he believes “OpenAI thought 4.5 was worse than Claude 3.6 Sonnet at coding and, from OpenAI’s perspective, this is a big disaster.” Their big pretrained model couldn’t match Anthropic’s smaller one.
Then GPT-5 came along this summer, reversing the trend set by every GPT model that came before. Previous GPT releases were roughly two orders of magnitude larger than earlier versions. Had GPT-5 continued the trend, it would have required a staggering 10^27 FLOPs of compute for pretraining. That’s enough data processing to repeat GPT-2’s entire training run a million times over, and equivalent to running a standard laptop for 30m years. Instead, GPT-5 backtracked, using less pretraining compute than its predecessor, according to Epoch.
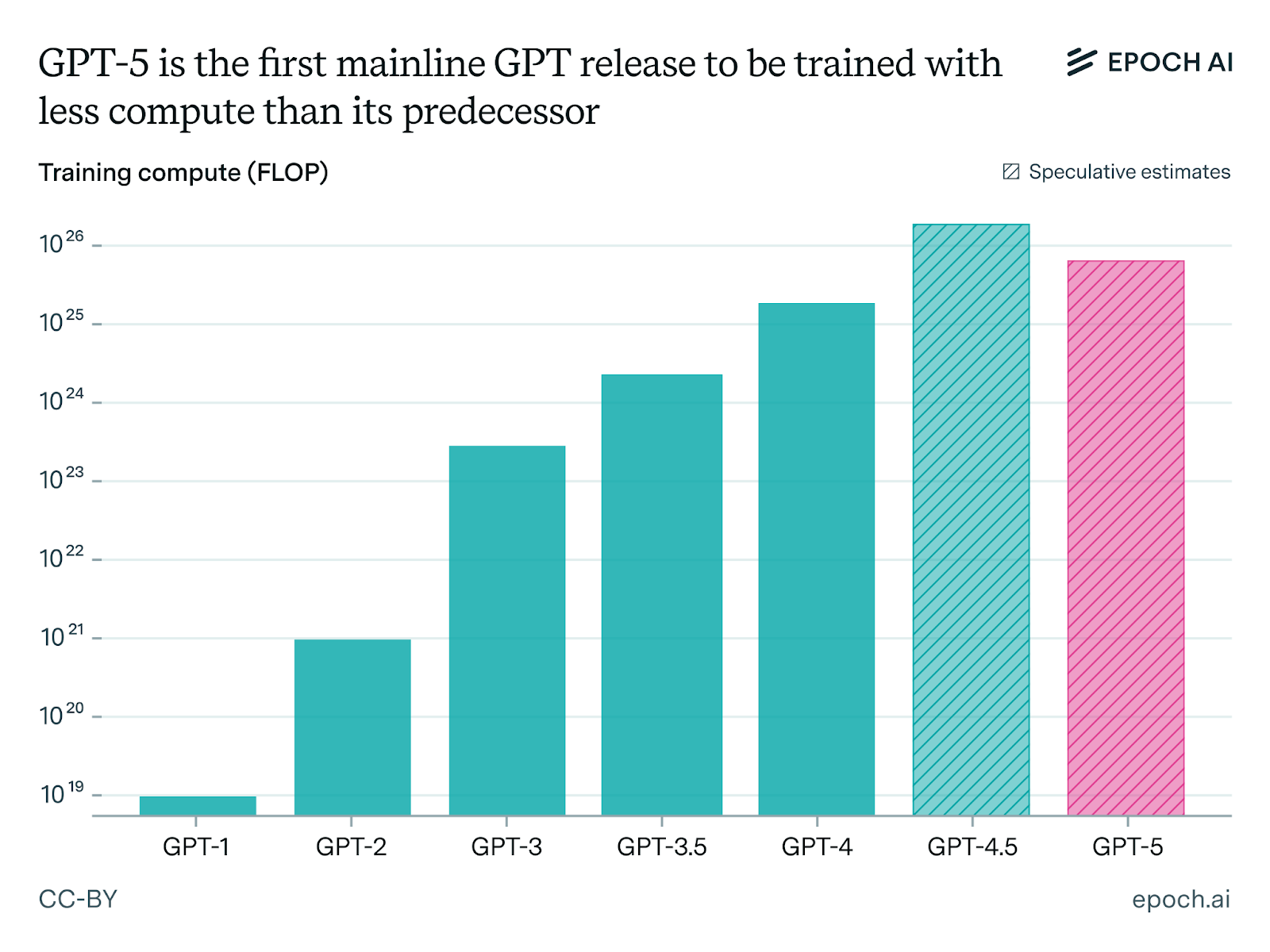
It seemed to suggest the headlines were correct — scaling is dead.
And yet, many industry watchers seem to believe reports of scaling’s demise are greatly exaggerated. Former OpenAI chief research officer Bob McGrew tweeted explicitly that “pre-training isn’t dead.” Researchers from Epoch expect that GPT-6 will resume the original scaling trend, requiring more pretraining compute than GPT-4.5.
The main arguments against the end of scaling suggest that its recent underuse and underperformance are driven by two temporary limits.
The first of these is a physical one: even the richest AI companies need time to build data centers sufficient to sustain exponential growth. The second is economic: researchers discovered cheaper ways to turn compute into performance. Together, these led to a pause, not a halt, in pretraining’s dramatic scaling.
When it comes to the physical constraint, the core issue is that AI companies simply ran out of GPUs. Epoch’s You estimates that OpenAI had around 500,000 GPUs at the start of this year. A training run for 10^27 FLOPs would take at least 200,000, he says, and likely more. Leaked data analysed by research org SemiAnalysis suggests OpenAI trained GPT-4 on around 25,000 Nvidia A100 GPUs for 90 to 100 days. You says today’s mainline H100 chips are about three times as good as the older A100s, meaning that simply scaling the compute needed to 100x a pretraining run would require 800,000 chips running for months.
That all means that OpenAI would likely have had to tie up around half of their GPUs for three months to do one training run. That, says You, “would be pretty irresponsible.” OpenAI needs those chips to run the inference that actually generates outputs, and to run training experiments. For example, one estimate suggests that 44% of that total compute is used for inference, meaning only around half their compute is available for training or experiments.

It’s not that the AI companies are growing their computing power slowly — surprise at the lack of compute put into new training reflects how aggressively they’ve scaled until now. Releasing a one hundred times larger model every two years would demand a tenfold increase in capacity each year, which, You says, is unrealistic. A new model every three years, he says, might be feasible, though that still requires an ambitious five-fold increase in compute every year.
Former OpenAI researcher Rohan Pandey recently claimed in a post on X that people were prematurely jumping to “pretraining is over” before seeing the results of the eye-catching investment in computing power. “Building projects like stargate and colossus2 to actually 100x gpt-4 compute takes time, let the labs cook,” he said.
Colossus, xAIs titanic data center in Memphis, Tennessee, is thought to be the only single center large enough for such a training run. In what is probably not a coincidence, xAI is the only company that some suggest might have completed a training run on 10^27 FLOPs — though that claim is dubious, with other estimates placing it closer to 10^26 FLOPs. That means that, in addition to tying up their chips for months, the other companies would be forced to use less-efficient multi-cluster training — which would involve connecting up multiple data centers in different locations to work on a training run together — if they attempted to complete a run this size.
The second reason is less about capacity, and more about the availability of alternatives. Researchers have found smarter ways to use their limited compute, which produced surprising improvements in models such as Deepseek or Anthropic’s Haiku. The past year has seen the rise of the reasoning paradigm, where companies pour their compute into improving models that have already gone through resource-intensive pre-training. For a time, that has offered comparable performance gains for a tiny fraction of the cost.
“There’s a lot of low-hanging fruit in reasoning still. But pre-training isn’t dead, it’s just waiting for reasoning to catch up to log-linear returns,” McGrew posted, blaming the pretraining scaling pause on this temporary glut of alternative options.
The big AI companies also invested heavily in algorithmic efficiency. “These companies are throwing a lot of total compute at experiments, trying to figure out which training recipes work best,” says You. Sholto Douglas, who researches scaling reinforcement learning at Anthropic and formerly DeepMind, said on a podcast earlier this year that such experiments are essential before committing to lengthy, costly pretraining runs: “You want to be sure that you’ve algorithmically got the right thing, and then when you bet and you do the large compute spend on the run, then it’ll actually pay off.”
In theory, those experiments will also inform approaches to large scale pretraining. Grok 4 was pretrained on more data than any other model to date, yet it wasn’t assessed to be markedly better than smaller models like GPT-5 or Claude Opus 4. Some suspect that’s because it lacks the algorithmic improvements that the other labs are currently investing heavily in. “I know Grok spent a whole bunch of money. They kind of tried to brute force their way to a result,” says Andrew Lohn, Senior Fellow at Georgetown’s Center for Security and Emerging Technology (CSET) and former National Security Council staffer. “Algorithms are hard, and money is costly, but easy.”
Ultimately, the choice comes down to economics, according to Lohn. Companies face a three-way trade off between pretraining, post-training, and inference.
Over the past year, that tradeoff didn’t favor pretraining. Companies lacked the computing resources to both scale up pre-training and run the inference and experimentation to make developing new models more efficient and effective. They also lacked the total compute in one location to do a big enough training run efficiently, even if they had forgone other uses for it.
OpenAI could have waited another year to release a GPT-5 model in the hopes they could produce a significantly-improved, scaled-up model. But they were under intense market pressure to release a new, superior model. They couldn’t release an efficient model that scaled pre-training to the next order of magnitude by summer 2025. But OpenAI could release a superior reasoning model in that time frame with less pretraining than its predecessor, so they did.
Yet the constraints that made that decision seem sensible are now changing.
Companies are rapidly expanding their computing resources, with multi-billion dollar deals that include huge new data centers that will be capable of massive pretraining runs. This year alone, Microsoft plans to invest $80b in data centers for AI, and Google’s Alphabet stepped up its capital expenditure plans this year to $85b to build out data center capacity. Looking further ahead, OpenAI has done a series of deals to expand computing power that could see it spend more than $1t.
The results of the investment are starting to become available. OpenAI’s Stargate campus in Abilene, Texas has just come online, with further expansion already underway. Altman tweeted in July that they would bring more than 1m GPUs online by the end of the year, a figure that You thinks they might have already hit.
Meanwhile, the previous low-hanging fruit is no longer so easy to reach. The resources needed to do effective post-training have grown so much that the difference in cost is becoming comparable. Epoch researchers note that post-training “current growth rates likely can’t be sustained for much more than a year.” As a result, huge pretraining runs might again become an attractive option.
That means companies could soon ratchet up to the next order of magnitude for pretraining scale. But that will likely take a while. You estimates that we won’t see a new 10^27 pretraining run until 2027.
What will happen at levels beyond that? There are bottlenecks that companies are already working to solve — generating better synthetic data, securing enough compute, and improving algorithm efficiency. So the question is, if those are overcome and 10^27 scale pre-training runs are launched, will the resulting models smash expectations? Or will they hit new, even thornier problems?
There’s plenty of life in scaling yet, but until it becomes feasible and economical again, we won’t get to see how much further it can take us.
The author’s partner works at Google DeepMind. The author also provided copy-edits for the Epoch update that served as a key source for this post.
 | A guest post by
|