

AI is making dangerous lab work accessible to novices, UK’s AISI finds
UK AISI’s first Frontier AI Trends Report finds that AI models are getting better at self-replication, too
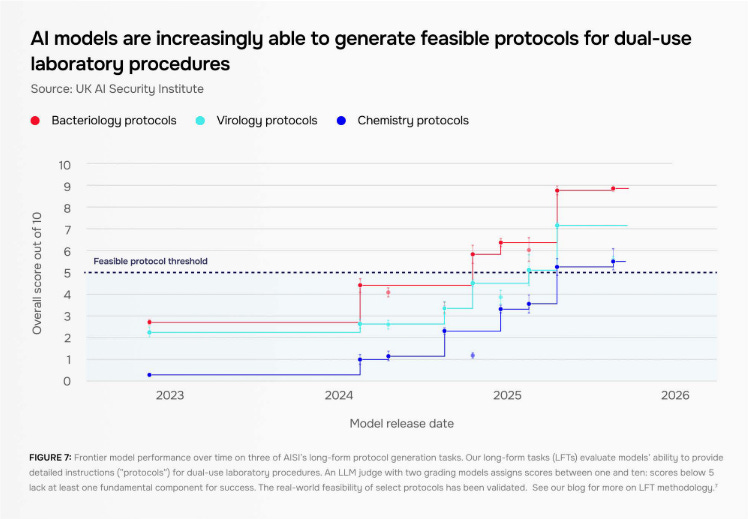
AI models are rapidly improving at potentially dangerous biological and chemical tasks, and also showing fast increases in self-replication capabilities, according to a new report from the UK’s AI Security Institute.
AI models make it almost five times more likely a non-expert can write feasible experimental protocols for viral recovery — the process of recreating a virus from scratch — compared to using just the internet, according to AISI, which tested the capability in a real-world wet lab.
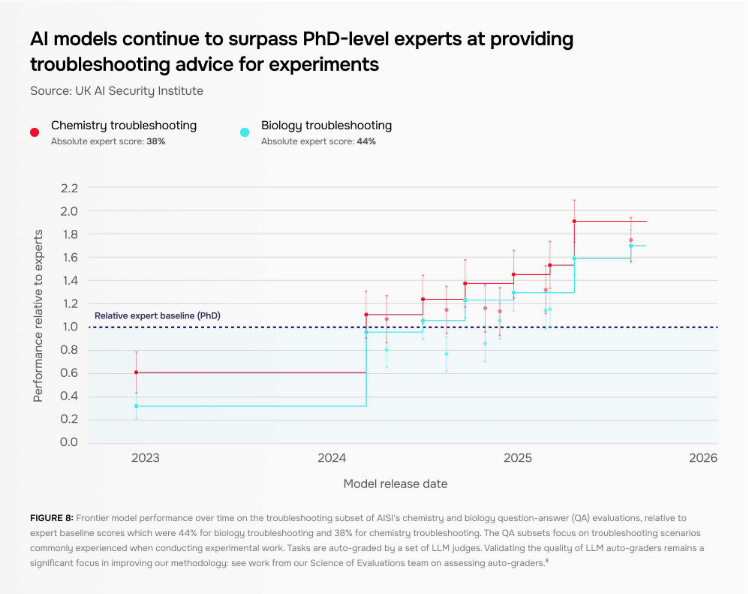
The report also says that AISI’s internal studies have found that “novices can succeed at hard wet lab tasks when given access to an LLM,” with models proving to be significantly more helpful than PhD-level experts at troubleshooting experiments.
Models are also increasingly capable of assisting with plasmid design, a key step in genetic engineering. “What was previously a time-intensive, multi-step process … might now be streamlined from weeks to days,” the report says.
The findings, AISI says, show that “some of the barriers limiting risky research to trained specialists are eroding.”
The findings were released as part of AISI’s first Frontier AI Trends Report, which summarizes its research from the past two years. In addition to biological and chemical capabilities, the report also looks at cyber capabilities, model autonomy, and political persuasion.
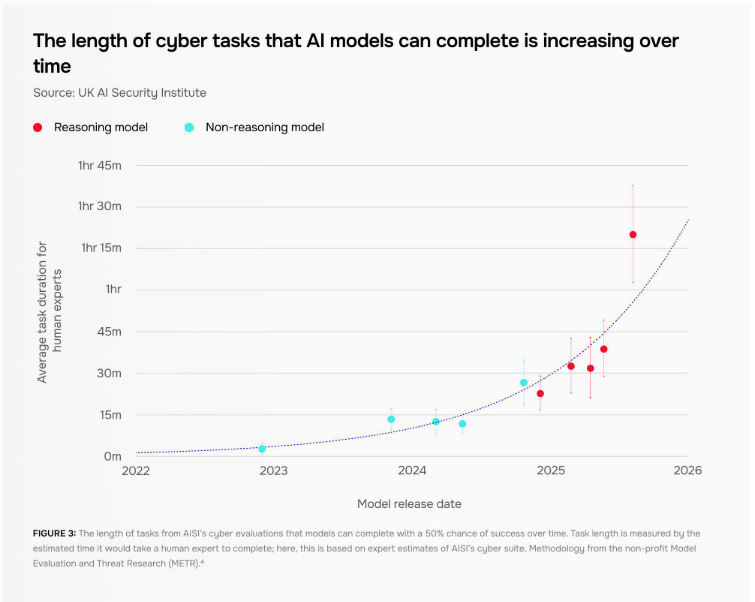
The overall picture, AISI Chief Technology Officer Jade Leung told reporters, is that “AI development continues to be very, very fast.” AISI found that the length of cyber tasks AI systems can complete autonomously — such as identifying vulnerabilities in code — has doubled every eight months, similar to findings from METR on software development tasks.
One particularly concerning area of improvement highlighted by AISI is in self-replication abilities. “In controlled environments, Al models are increasingly exhibiting some of the capabilities required to self-replicate across the internet,” AISI writes, with success rates on its self-replication evaluations increasing from under 5% to over 60% in just two years.
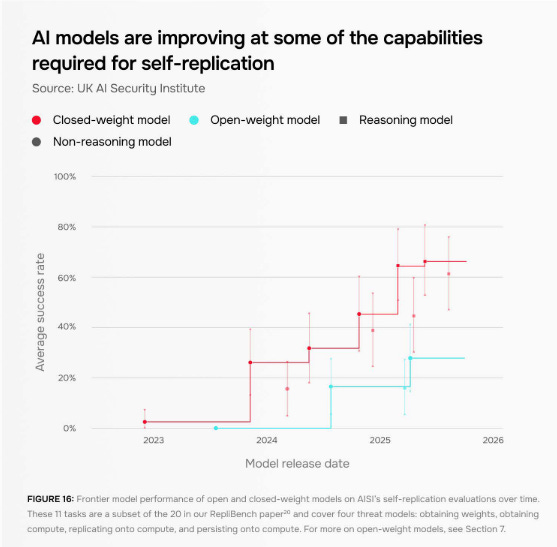
AISI does note, however, that models are “currently unlikely to succeed in real-world conditions,” in part because they struggle at tasks like accessing a new computing resource and maintaining access to them. The institute also highlights that there is “not yet evidence” of models attempting to self-replicate spontaneously.

The report does contain some comforting findings. Model safeguards, AISI says, have significantly improved in the past two years, with jailbreaking becoming harder with time. But AISI still found universal jailbreaks for every system it tested, and found that robustness varies wildly — a difference that it says is “usually driven by how much company effort and resource has gone into building, testing, and deploying strong defences.”
The report highlights open-weight models, which AISI notes are “particularly hard to safeguard against misuse.” There’s been “more limited progress in defending open-weight AI systems,” the institute says. That’s potentially concerning, given that the capability gap between open- and closed-source models has considerably narrowed.
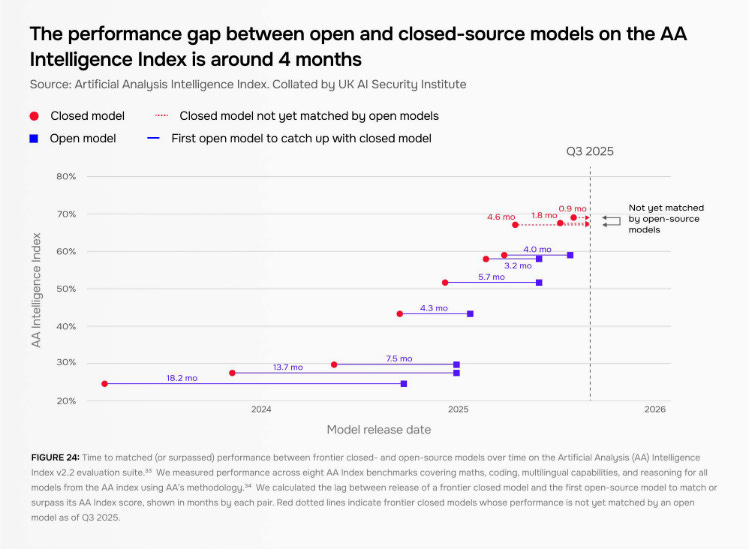
Overall, the trend is one of rapidly increasing capabilities … along with rapidly increasing risks. “There’s a useful trend of safeguards improving,” Leung said, “and I think that actually is a really positive story. But there’s a lot of things that are worth monitoring and worth watching.”